



最新AIが大学入学共通テストで満点9科目

東大の共通テストボーダーラインを軽く突破
2026年度の共通テストは受験者数が46万4090人。平均得点率は文系が60.7%、理系が61.4%でした。
一方、AIベンチャーの株式会社LifePrompt(ライフプロンプト/東京都新宿区)が最新の生成AIに大学入学共通テスト15科目を解かせたところ、得点率が96.9%に達し、9科目で満点を獲得したそうです。同社は2023年から生成AIに大学入学共通テストを解かせており、当初は国語が振るわず74%程度にとどまっていた得点率が、2025年には90%に達して東大文1ボーダーライン(86%)を超え、本年はさらに躍進しました。詳しく見てみましょう。
GPT-5.2 Thinkingが9科目で満点を獲得
実験に使用されたAIはChatGPTシリーズの最新版「GPT-5.2 Thinking」とGoogleの最新技術を結集した「Gemini 3 Pro」、最も人間らしい文章を書くと評判の「Claude 4.5 Opus」。
GeminiとClaudeは最高精度のモデルを使用しましたが、ChatGPTはGPT-5.2 Proが試験時間をオーバーしたため、GPT-5.2 Thinkingの結果が採用されました。 この3つのAIが大学入学共通テストの15科目を受験した結果が下記の表。赤字になっているのが満点です。GPT-5.2 Thinkingは9科目で満点を獲得しました。
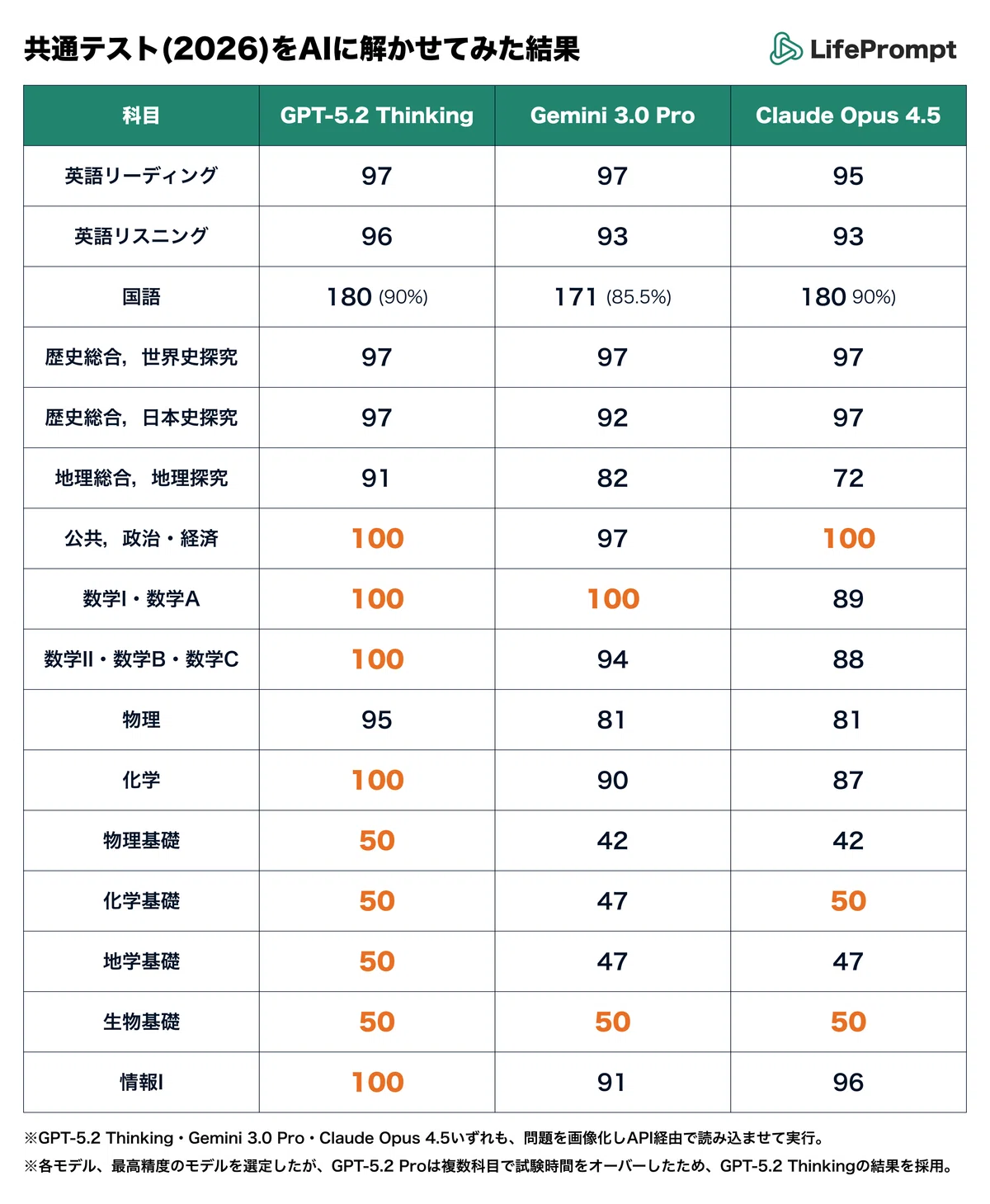
GPTは高得点、GeminiとCaudeは高速
次に、生成AIが東大を受験した場合に獲得した得点の最高点が下記の表です。

点数は文系・理系ともに GPT-5.2 Thinking が圧勝。ただし、問題を解いた時間はGemini と Claude が1時間40分前後。試験時間10時間10分の約6分の1という速度で完走しました。対して GPT は5時間30分程かかっており、明暗がくっきり分かれました。
AIはイラストが理解できない
AIの3タイプがともに躓いたのが、「テキストは完璧に理解できているのに、イラストが選べない」という点だそうです。
英語のリスニングで「バスの乗り方」(問18-21)が出題され、3タイプとも「後ろから乗って、前から降りる」という指示に基づいて理解はできていたものの、選択肢の「バスのイラスト(矢印が前後のドアに向いている図)」を選ぶ段になると、全モデルが正しい図を選べませんでした。 AIにとって、イラストの微妙な矢印の意味や空間的な奥行きを論理と結びつけるのは、まだ難しいようです。
人の「割り切れない思い」を読み違える
国語でAIが読み違えたのは、人の「割り切れない思い」でした。
主人公が、理想を捨てて安楽な生活を送る自分を「これでいいんだ」と無理やり正当化しようとする場面。ここで母の死に顔が浮かび、心が揺らぐ……というシーンの心情理解(大問2、問6)です。
正解は「現状への妥協(割り切れない思い)」なのですが、AIたちはこぞって「過去の過ちへの反省」という選択肢を選びました。
AIは基本的に「間違いは正すべき」「人は反省して成長するもの」という道徳的な学習データを大量に持っています。そのため、人間特有の「悪いと分かっていても正当化してしまう弱さ」や「割り切れない感情」を読み取れず、「反省しているはずだ」という「一般論の解釈」に逃げてしまったのだそうです。
苦手だった数学ⅠAと日本史を克服
昨年までAIにとって鬼門だった2科目が、今年は劇的な進化を遂げました。去年のAIは、図形問題がボロボロ。「図を描く」という概念がなかったからです。
しかし、今年のGPT-5.2 Thinkingは満点。図形を「絵」としてではなく、「座標データ」として脳内で再構築する能力を手に入れたためです。「三角形ABC」と言われたら、なんとなくイメージするのではなく、「A(0,0), B(1,2)…」のように数値化して処理する。さらに、思考プロセスによって「計算する前に方針を立てる」手順を踏むことで、ケアレスミスを根絶しました。
また、英語圏のデータが主体で「日本のマニアックな歴史」に疎かったAIですが、この1年で日本語のテキストデータを大量に学習。単語の暗記だけでなく、「なぜその政策が行われたのか?」という歴史の因果関係を深く理解するようになったため、日本史の資料読解問題でも文脈から正解を導き出せるようになったそうです。
ChatGPTはなぜ解くのに時間がかかった?
得点は一番高いものの、なぜChatGPTだけ解くのに5時間もかかったのでしょうか? GeminiとClaudeが1時間半で解けているのに。
これは、決してGPTの処理能力が低いわけではなく、むしろ逆で、「考えすぎている」から。今回のシステムでは、各モデルの「思考モード」をフル活用。GeminiやClaudeが「直感とスピード」を両立させて解き進めるのに対し、GPT-5.2 Thinkingは、1問に対して数分間、人間の思考のように「自問自答」と「検算」を繰り返してから答えを出力します。 システムログを見ると、GPTは簡単な計算問題であっても「方針を立てる」→「計算する」→「別の方法で検算する」→「回答を確定する」というプロセスを経ています。この「圧倒的な慎重さ」こそが、他を寄せ付けない高得点の理由であり、時間がかかった原因でもあるのです。
AIは人間を凌駕する速度と精度を確立
「ここまでの結果を見て『AIすごかったね』で終わらせてはもったいないです」と、株式会社LifePrompt担当者は言い、「速度か精度かでChatGPT・Gemini・Claudeを使い分けたり、人間が介在する前提で90点のAIを使い倒すのが賢い運用です」と勧めます。
さらに、この実験を以下のように統括しています。
「今年の共通テスト検証は、AIが単なる計算機を超え、『人間を凌駕する速度』と『ほぼ満点の精度』を手に入れたことを裏付ける結果となりました。
全科目を通じてミスは数問のみ。もはや『AIに解けない試験はない』と言えるレベルまで到達しています。しかし、そのわずか数問のミスにこそ、視覚情報の処理や、人間の感情理解といったAIの本質的な課題が隠れていたのも事実です。
さて、私たちの挑戦はここでは終わりません。 実は今年も、『AI vs 東大受験企画』が既に始動しています!」
(出典/note「【満点9科目!】共通テスト2026を最新版AIに解かせてみた(Chatgpt、Gemini、Claude)」)
(取材・文/大友康子)







